- There is enough traffic to validate a few hypotheses at a time.
- There are separate teams responsible for onboarding experience, paywalls, and monetization strategy.
General splitting rules
Splitter in Qonversion Experiments works in the following way:-
At the top of the processing funnel, Splitter receives User_A.
- Splitter receives User_A when the
remoteConfigmethod is called
- Splitter receives User_A when the
- Splitter sorts experiments with selected Context key by Start date and checks if User_A can be assigned to each experiment.
-
When Splitter validates if User_A matches experiment rules, it checks the following attributes:
- Segmentation rules (Country, App version, etc.)
- Level of traffic allocation (30%, 50%, 70%, etc.)
-
If User_A matches segmentation rules, he is assigned to a specific group inside the experiment. Otherwise, Splitter returns to Step #2 to check User_A against the following experiment in the queue.
- Please note, if you have the traffic level in the first launched experiment (sorted by start date) set to 70% and in the second - 30%, that means that your second experiment is exposed for (100% - 70%) * 30% = 9% of all users. Set the traffic level to 100% for the second experiment in case you want to use all the remaining users from the first experiment. Below you can find some examples that help understand this approach better.
Cross-context experiments
Please note that a User can be assigned to a few experiments with different Context keys at a time.To turn off exposure to cross-context experiments, please use the Attached active experiment and Attached experiment context key segmentation options.Example #1
Let’s consider the case of launching two experiments with the same Context key at a time:- One for users from the UK, 100% traffic allocation level. Start date = 09.03.23
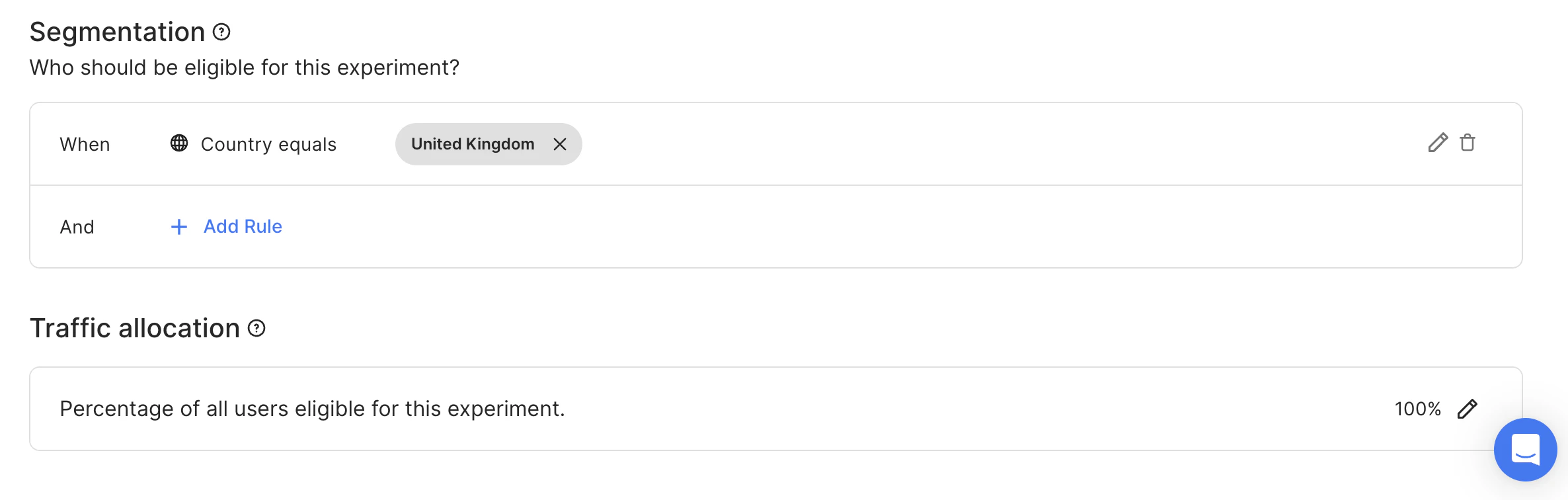
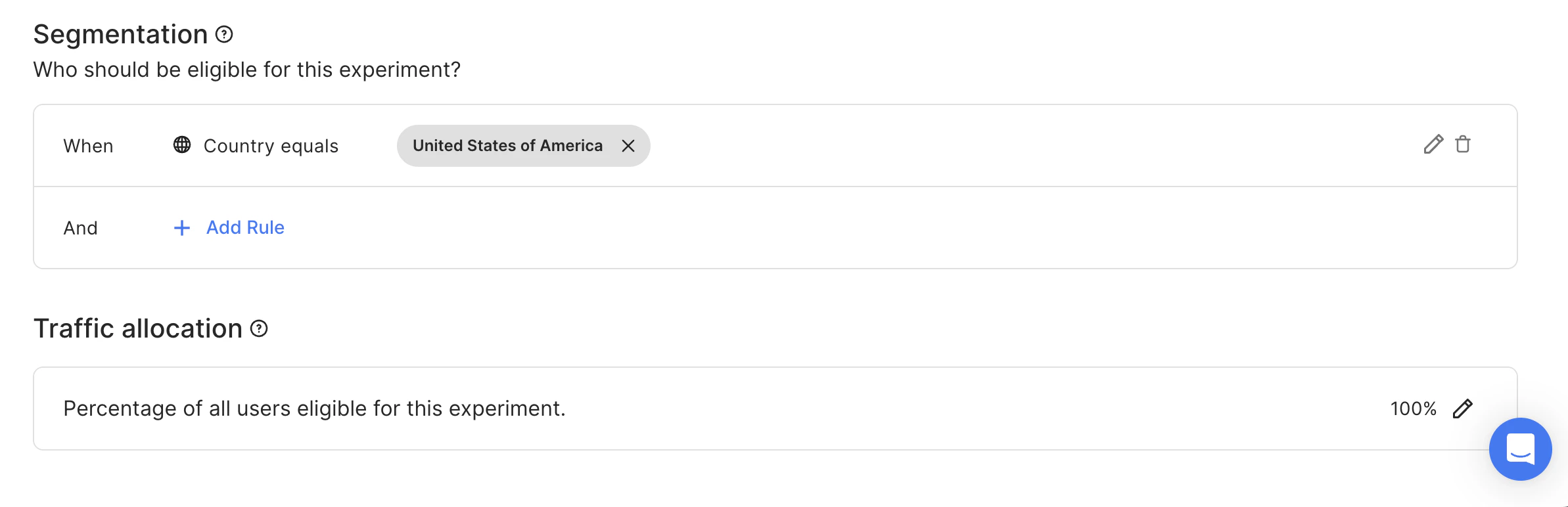
- One for users from the US. 100% traffic allocation level. Start date = 15.03.23.
- 100% of users from the UK are assigned to experiment #1.
- 100% of users from the US are assigned to experiment #2.
- None of the remaining users have been assigned to experiments with the selected Context key.
Example #2
Let’s consider the case of launching two experiments with the same Context key at a time but with similar segmentation settings:- One for users from the UK, 70% traffic allocation level. Start date = 09.03.23
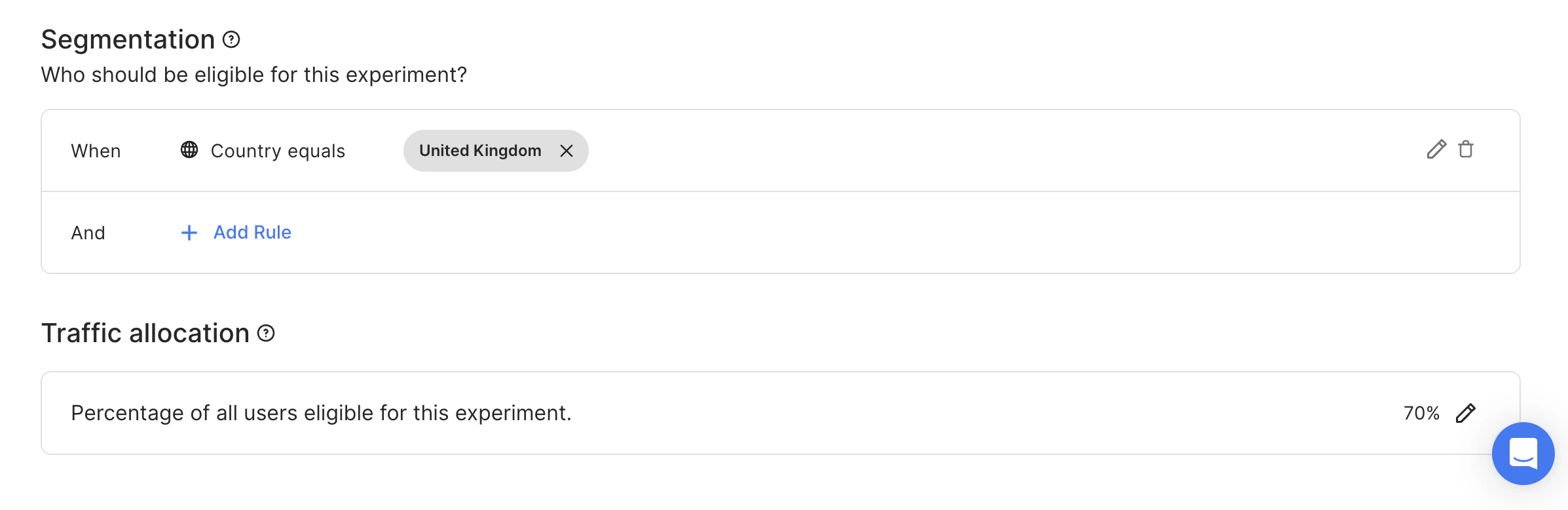
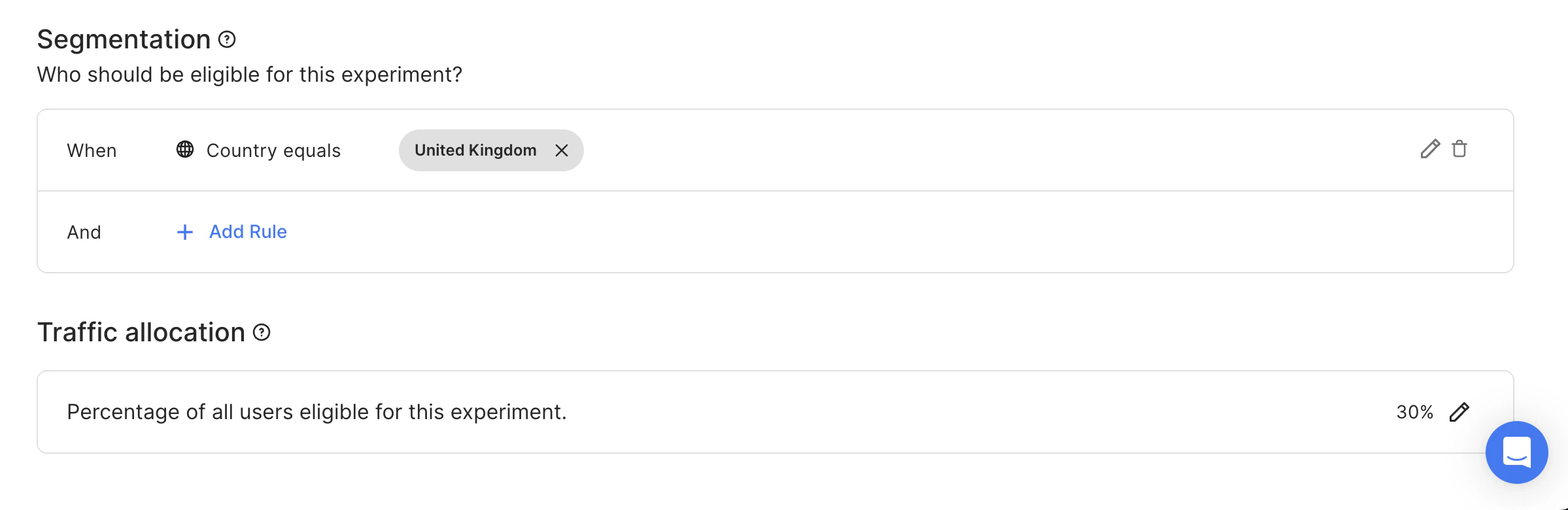
- Another one is for users from the UK as well. 30% traffic allocation level. Start date = 15.03.23.
- 70% of users from the UK are assigned to Experiment #1 (with Start date = 09.03.23).
- (100% - 70%) * 30% = 9% of users from the UK are assigned to Experiment #2 (with Start date = 15.03.23).
- 100% - 70% - 9% = 21% of users from the UK are not assigned to any experiment.
- 100% of users outside the UK have not been assigned to experiments with the selected Context key.
Stop experiments Apple App Store